Google's Distributed Monolith: 42 Regions That Failed as One
Google operates 42 cloud regions. On June 12, 2025, they all crashed simultaneously. That's not distributed infrastructure—it's a monolith with extra steps. The outage reveals how the industry systematically builds the appearance of distribution while eliminating every blast radius boundary.
Google operates 42 cloud regions across 5 continents. On June 12, 2025, every single one of them crashed at the same moment.
That’s not distributed infrastructure. That’s a monolith wearing a clever disguise.
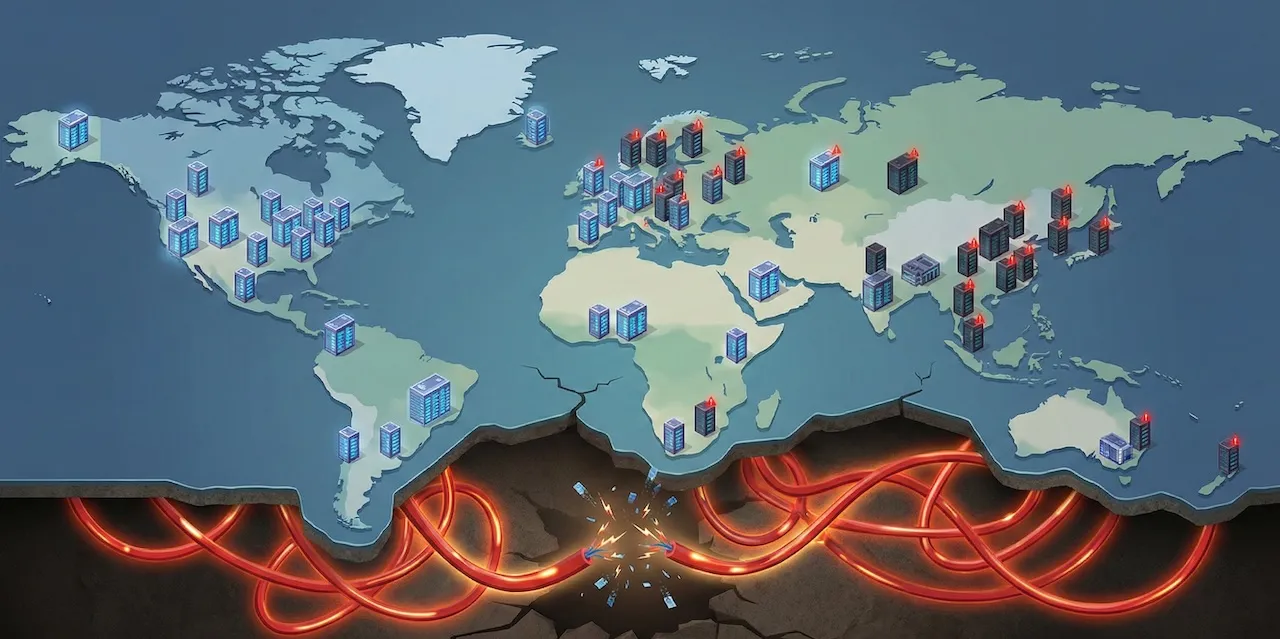
The whole promise of distributed systems is blast radius containment. When something fails, the failure stays local. Region A goes down, Regions B through Z keep running. That’s why you pay the complexity tax—the operational overhead, the eventual consistency headaches, the network partition nightmares. You tolerate the pain because isolation buys you resilience.
Google charged enterprise customers for 42 independent regions. They delivered one giant synchronized failure domain.
The Chokepoint Nobody Mentioned
Service Control is Google’s internal API management system. Every API call to Google Cloud passes through it for authentication, rate limiting, quota enforcement, and access control.
76 products depend on it.
Cloud Storage. BigQuery. Compute Engine. Cloud Run. Kubernetes Engine. Pub/Sub. All of it routes through Service Control before anything happens. Miss a single request through this system, and the corresponding API call fails.
On paper, this looks like textbook distributed systems design. Service Control runs in all 42 regions. Each region has its own copy. If one region fails, the others keep running. Redundancy. Fault tolerance. Exactly what you’d expect from the company that wrote the book on large-scale distributed systems.
So what went wrong?
Instant Sync: A Feature That Became a Weapon
On May 29, 2025, the Service Control team shipped a new feature for quota policy validation. The code had a path that could receive a null value. When it did, the binary crashed. A null pointer exception—the kind of bug that wouldn’t survive a first-semester code review.
The bug sat dormant for two weeks. It was waiting for the right configuration.
At 10:49 AM Pacific on June 12, an automated process wrote a quota policy with a null value to one region’s database. Within seconds, Service Control binaries in all 42 regions were crashing.
How does a bad write in one region crash every region simultaneously?
Spanner.
Google stores Service Control’s quota policies in a globally-replicated Spanner database configured for instant synchronization. When a policy is written anywhere, all 42 regions receive it immediately. This was a deliberate product decision—users get real-time quota updates across the globe.
No canary release. No blue-green deployment. No geographic rollout. No segment-based rollout. The entire planet became one deployment target.
Google invented several of these deployment safety techniques. They published papers about them. They gave conference talks. They open-sourced tooling. They chose not to use any of it for the system that 76 products depend on.
Someone decided that giving users instant quota updates was more important than giving operators time to notice problems. That tradeoff looked reasonable right up until a single null value detonated across 42 regions simultaneously.
The Recovery That Made It Worse
Google’s operations team isn’t amateur. They identified the root cause in 10 minutes. Wrote a patch. Deployed it globally within 40 minutes. That’s genuinely impressive incident response.
BUT, the outage lasted 6 hours and 41 minutes.
Why? Because they created a thundering herd—but not in the way you might expect.
When Google deployed the patch, Service Control tasks across all 42 regions began restarting simultaneously. Each restarting instance needed to reconnect to its downstream dependency: the regional Spanner database holding quota policy metadata. Thousands of Service Control tasks hit Spanner at the same moment.
Spanner buckled.
The solution for this has been industry standard for decades: randomized exponential backoff on startup. Stagger your restarts. Add jitter so thousands of instances don’t all reconnect at once.
Service Control’s restart logic had neither randomization nor exponential backoff. Every instance that came up immediately hammered Spanner. Spanner’s inability to handle the connection storm meant Service Control couldn’t fully recover. The us-central1 region—one of the largest—kept failing to stabilize.
The operations team spent nearly three more hours manually throttling restarts and distributing load. Entry-level distributed systems hygiene in Service Control’s own startup behavior would have prevented this entirely.
The Dependency Inversion
If the Google outage were isolated, it would be an embarrassing incident for one company. The Cloudflare cascade makes it an industry indictment.
Cloudflare is infrastructure. Their products—DDoS protection, CDN, DNS, Workers—form a foundation layer that other services build on. The expected dependency hierarchy: applications depend on platforms, platforms depend on infrastructure. Infrastructure providers should be foundational—platforms depend on them, not the other way around.
But Cloudflare broke this rule. They deployed Workers KV—a critical component powering 22 of their core systems—exclusively on Google Cloud. An infrastructure provider made itself dependent on a platform provider.
So, when Google Cloud went down, Cloudflare went down with it.
Cloudflare’s incident report delicately refers to “a third-party cloud provider” without naming Google. Their remediation: “removing the dependency on any single provider.” They’re accelerating migration to their own R2 storage.
The defense for this architecture presumably sounded reasonable: Google’s SLA is better than anything Cloudflare could build themselves. Why reinvent infrastructure when you can rent it from the best?
The answer arrived on June 12.
The Distributed Monolith Pattern
What happened to Google isn’t a freak accident. It’s a pattern. Call it the distributed monolith.
The distributed monolith looks sophisticated. Multiple regions. Global replication. Automatic failover. All the buzzwords that justify enterprise pricing and make architecture diagrams look impressive.
But under the surface, every isolation boundary has been “optimized” away.
Global configuration systems eliminate regional independence. Instant synchronization eliminates deployment windows. Shared dependencies eliminate blast radius containment. Unified retry logic eliminates recovery time.
The system is distributed in topology but monolithic in failure mode.
The optimization pressure is relentless. Product managers want instant global consistency. Finance wants fewer isolated systems to maintain. Operations wants unified tooling. Every force in the organization pushes toward removing the boundaries that make distribution meaningful.
The result is a system that charges you for 42 regions but delivers one. You get the complexity costs of distribution and the fragility costs of centralization simultaneously.
What Distribution Actually Means
Distribution isn’t about replication. It’s about isolation.
Copying your service to 42 locations doesn’t make it distributed. It makes it replicated. The distinction matters when you ask: can Region A fail without taking down Region B?
If the answer is no, you don’t have 42 regions. You have one region that happens to be stored in 42 places.
True distribution requires accepting the costs of isolation. Regional configuration that can diverge. Deployment rollouts that take time. Data consistency that’s eventual rather than instant. Circuit breakers that let parts of the system fail independently.
These constraints feel like limitations. But that’s the whole point.
The boundaries that slow you down during normal operation are the boundaries that save you during failure. The deployment friction that annoys your product manager is the deployment friction that prevents a null pointer exception from detonating globally.
Google’s architecture eliminated every boundary. They got a faster, simpler system that looked impressive on paper. They got 6 hours and 41 minutes of global outage when the paper met reality.
The Industry-Wide Problem
The uncomfortable truth: this pattern is everywhere.
Cloudflare—an infrastructure company—deployed critical systems on a single cloud provider with no redundancy. An infrastructure provider made themselves dependent on a platform provider.
How many other “distributed” systems are actually distributed monoliths? How many global architectures have hidden chokepoints? How many multi-region deployments share a single configuration source that could take everything down at once?
The distributed monolith is the default outcome when you optimize for developer experience, operational simplicity, and feature velocity without treating isolation as a hard constraint. Every organization faces the same pressures Google faced. Most make the same tradeoffs.
The next June 12 is already being architected somewhere. A team is choosing instant global sync over staged rollout. A platform is adding a shared dependency that becomes a chokepoint. A configuration system is being centralized for “simplicity.” Each decision is locally rational and globally catastrophic.
Distribution is a discipline, not a topology. It requires actively maintaining boundaries that everything in your organization wants to eliminate. It means accepting constraints that feel unnecessary until the day they’re the only thing standing between you and a global outage.
The companies that understand this will build systems that actually fail independently. The rest will build distributed monoliths and discover the difference when it’s too late.
Google’s 42 regions crashed as one. That’s not a bug in their implementation. It’s the logical consequence of their architecture. They built a monolith and called it distributed.
Don’t make the same mistake.
Liked this?
New essays and project notes, delivered to your inbox. Unsubscribe anytime.